Our Architectural Risk Analysis, which you can download here, identifies 78 specific risks associated with a generic ml system.
Click on a component to see the associated risks.
In addition to risks grounded in components, there are a number of system-wide risks that emerge
only at the system level or between and across multiple components.
Many data-related component risks lead to bias in the behavior of an ML system. ML systems
that operate on personal data or feed into high impact decision processes (such as credit scoring,
employment, and medical diagnosis decisions) pose a great deal of risk. When biases are aligned
with gender, race, or age attributes, operating the system may result in discrimination with respect
to one of these protected classes. Using biased ML subsystems is is definitely illegal in some
contexts, may be unethical, and is always irresponsible.
When an ML system with a particular error behavior is integrated into a larger system and its
output is treated as high confidence data, users of the system may become overconfident in the
operation of the system for its intended purpose. A low scrutiny stance with respect to the overall
system makes it less likely that an attack against the ML subsystem will be detected. Developing
overconfidence in ML is made easier by the fact that ML systems are often poorly understood and
vaguely described. (See [output:5:transparency].)
Any ML system can and will make mistakes. For example, there are limitations to how effective the
prediction of a target variable or class can be given certain input. If system users are unaware of the
subtleties of ML, they may not be able to account for “incorrect” behavior. Lost confidence may
follow logically. Ultimately, users may erroneously conclude that the ML system is not beneficial to
operation at all and thus should be disregarded. In fact the ML system may operate on average
much more effectively than other classifying technology and may be capable of scaling a decision
process beyond human capability. Throwing out the baby with the bathwater is an ML risk. As an
example, consider what happens when self-driving cars kill pedestrians.
Confidence related risks such as [system:2:overconfidence] and [system:3:loss of confidence] are
focused on the impact that common ML misunderstandings have on users of a system. Note that
such risks can find their way out into society at large with impacts on policy-making (regarding
the adoption or role of ML technologies) and the reputation of a company (regarding nefarious
intentions, illegality, or competence). A good example is the Microsoft chatbot, Tay, which learned
to converse by parsing raw twitter content and ultimately exhibited racist, xenophobic, and sexist
behavior as a result. Microsoft pulled the plug on Tay. Tay was a black eye for ML in the eyes of the
public.32:jagielski
When ML output becomes input to a larger decision process, errors arising in the ML subsystem
may propagate in unforeseen ways. For example, a classification decision may end up being treated
as imputed metadata or otherwise silently impact a conditional decision process. The evaluation of
ML subsystem performance in isolation from larger system context may not take into account the
“regret” this may incur. That is, methods that evaluate ML accuracy may not evaluate utility, leading
to what has been called regret in the ML literature.
When an ML subsystem operating within a larger system generates too many alarms, the subsystem
may be ignored. This is particularly problematic when ML is being applied to solve a security
problem like intrusion or misuse detection. False alarms may discourage users from paying
attention, rendering the system useless.
If ML system components are distributed, especially across the Internet, preserving data integrity
between components is particularly important. An attacker in the middle who can tamper with data
streams coming and going from a remote ML component can cause real trouble.
As always in security, a malicious insider in an ML system can wreak havoc. Note for the record
that data poisoning attacks (especially those that subtly bias a training set) can already be hard to
spot. A malicious insider who wishes not to get caught would do well to hide in the data poisoning
weeds.
Data may be incorrectly encoded in a command, or vice versa. When data and API information
are mixed, bad things happen in security. Know that APIs are a common attack target in security
and are in some sense your public front door. How do you handle time and state? What about
authentication?
Denial of service attacks have broad impact when service access impacts a decision process. When
an ML system fails, recovery may not be possible. If you decide to rely entirely on an ML system that
fails, recovery may not be possible, even if all of the data that feed the ML system are still around.
If we have learned only one thing about ML security over the last few
months, it is that data play just as important role in ML system security as the learning algorithm
and any technical deployment details. In fact, we’ll go out on a limb and state for the record that
we believe data make up the most important aspects of a system to consider when it comes to
securing an ML system.
Our usage of the term raw data in this section is all inclusive, and is not limited to training data
(which for what it’s worth is usually created from raw data). There is lots of other data in an ML
system, including model parameters, test inputs, and operational data.
Data security is, of course, a non-trivial undertaking in its own right, and all collections of data in an
ML system are subject to the usual data security challenges (plus some new ones).
Eventually, a fully-trained ML system (whether online or offline) will be presented with new input
data during operations. These data must also be considered carefully during system design.
Preserving data confidentiality in an ML system is more challenging than in a standard computing
situation. That’s because an ML system that is trained up on confidential or sensitive data will
have some aspects of those data built right into it through training. Attacks to extract sensitive
and confidential information from ML systems (indirectly through normal use) are well known.7:shokri
Note that even sub-symbolic “feature” extraction may be useful since that can be used to hone
adversarial input attacks.4:papernot
Data sources are not trustworthy, suitable, and reliable. How might an attacker tamper with or
otherwise poison raw input data? What happens if input drifts, changes, or disappears?8:barreno
Data are stored and managed in an insecure fashion. Who has access to the data pool, and why?
Access controls can help mitigate this risk, but such controls are not really feasible when utilizing
public data sources. This kind of risk brings to mind early attempts to create mathematically random
data for cryptographic security through combining sets of inputs that could ultimately be influenced
by an attacker (such as process id, network packet arrival time, and so on). Needless to say, entropy
pools controlled by an attacker are low entropy indeed. Ask yourself what happens when an
attacker controls your data sources.
Note that public data sources may include data that are in some way legally encumbered. An
obvious example is copyrighted material that gets sucked up in a data stream. Another more
insidious example is child pornography which is never legal. A third, and one of the most interesting
legal issues now is that there may be legal requirements to “delete” data (e.g., from a GDPR
request). What it means to “delete” data from a trained model is challenging to carry out (short
of retraining the model from scratch from a data set with the deleted data removed, but that is
expensive and often infeasible). Note that through the learning process, input data are always
encoded in some way in the model itself during training. That means the internal representation
developed by the model during learning (say, thresholds and weights) may end up being legally
encumbered as well.
Raw data are not representative of the problem you are trying to solve with ML. Is your sampling
capability lossy? Are there ethical or moral implications built into your raw data (e.g., racist or
xenophobic implications can be trained right into some facial recognition systems if data sets are
poorly designed)?9:phillips
Representation plays a critical role in input to an ML system. Carefully consider representation
schemes, especially in cases of text, video, API, and sensors. Is your representation rich enough
to do what you want it to do? For example, many encodings of images are compressed in a lossy
manner. This will impact your model, figure out how.
Text representation schemes are not all the same. If your system is counting on ASCII and it gets
Unicode, what happens? Will your system recognize the incorrect encoding and fail gracefully or
will it fail hard due to a misinterpreted mismatch?
Model confounded by subtle feedback loops. If data output from the model are later used as input
back into the same model, what happens? Note that this is rumored to have happened to Google
translate in the early days when translations of pages made by the machine were used to train the
machine itself. Hilarity ensued. To this day, Google restricts some translated search results through
its own policies.
Entangled data risk. Always note what data are meant to represent and be cognizant of data
entanglement. For example, consider what happens if a public data source (or even an internal
source from another project) decides to recode their representation or feature set. Note that “false
features” can also present an entanglement problem as the famous husky-versus-wolf classifier
demonstrated by acting (incorrectly) as a snow detector instead of a species detector. Know which
parts of your data can change and which should not ever change.10:sculley
Metadata may help or hurt an ML model. Make note of metadata included in a raw input dataset.
Metadata may be a “hazardous feature” which appears useful on the face of it, but actually
degrades generalization. Metadata may also be open to tampering attacks that can confuse
an ML model.11:ribeiro More information is not always helpful and metadata may harbor spurious
correlations. Consider this example: we might hope to boost performance of our image classifier
by including exif data from the camera. But what if it turns out our training data images of dogs are
all high resolution stock photos but our images of cats are mostly facebook memes? Our model will
probably wind up making decisions based on metadata rather than content.
If time matters in your ML model, consider time of data arrival a risk. Network lag is something
easily controlled by an attacker. Plan around it.
Always consider the technical source of input, including whether the expected input will always be
available. Is the sensor you are counting on reliable? Sensor blinding attacks are one example of a
risk faced by poorly designed input gathering systems. Note that consistent feature identification
related to sensors is likely to require human calibration.
If your data are poorly chosen or your model choice is poor, you may reach incorrect conclusions
regarding your ML approach. Make sure your methods match your data and your data are properly
vetted and monitored. Remember that ML systems can fail just as much due to data problems as
due to poorly chosen or implemented algorithms, hyperparameters, and other technical system
issues.
In order to be processed by a learning algorithm, raw input data often
must be transformed into a representational form that can be used by the machine learning
algorithm. This “pre-processing” step by its very nature impacts the security of an ML system since
data play such an essential security role.
Of special note in this component is the discrepancy between online models and offline models
(that is, models that are continuously trained and models that are trained once and “set”). Risks in
online models drift, and risks in offline models impact confidentiality.
Encoding integrity issues noted in [raw:5:encoding integrity] can be both introduced and
exacerbated during pre-processing. Does the pre-processing step itself introduce security
problems? Bias in raw data processing can impact ethical and moral implications. Normalization of
Unicode to ASCII may introduce problems when encoding, for example, Spanish improperly, losing
diacritics and accent marks.
The way data are “tagged and bagged” (or annotated into features) can be directly attacked,
introducing attacker bias into a system. An ML system trained up on examples that are too specific
will not be able to generalize well. Much of the human engineering time that goes into ML is spent
cleaning, deleting, aggregating, organizing, and just all-out manipulating the data so that it can be
consumed by an ML algorithm.
Normalization changes the nature of raw data, and may do so to such an extent that the normalized
data become exceedingly biased. One example might be an ML system that appears to carry
out a complex real-world task, but actually is doing something much easier with normalized data.
Destroying the feature of interest in a dataset may make it impossible to learn a viable solution.
When building datasets for training, validation, and testing (all distinct types of data used in ML
systems), care must be taken not to create bad data partitions. This may include analysis of and
comparisons between subsets to ensure the ML system will behave as desired.
Input from multiple sensors can in some cases help make an ML system more robust. However,
note that how the learning algorithm chooses to treat a sensor may be surprising. One of the major
challenges in ML is understanding how a “deep learning” system carries out its task. Data sensitivity
is a big risk and should be carefully monitored when it comes to sensors placed in the real world.
An attacker who knows how a raw data filtration scheme is set up may be able to leverage that
knowledge into malicious input later in system deployment.
If an attacker can influence the partitioning of datasets used in training and evaluation, they can in
some sense practice mind control on the ML system as a whole. It is important that datasets reflect
the reality the ML system designers are shooting for. Boosting an error rate in a sub-category might
be one interesting attack. Because some deep learning ML systems are “opaque,” setting up
special trigger conditions as an attacker may be more easily accomplished through manipulation of
datasets than through other means.8:barreno
Randomness plays an important role in stochastic systems. An ML system that is depending on
Monte Carlo randomness to work properly may be derailed by not-really-random “randomness.”
Use of cryptographic randomness sources is encouraged. “Random” generation of dataset
partitions may be at risk if the source of randomness is easy to control by an attacker interested in
data poisoning.
Assembled data must be grouped into a training set, a validation set, and a
testing set. The training set is used as input to the learning algorithm. The validation set is
used to tune hyperparameters and to monitor the learning algorithm for overfitting. The test set
is used after learning is complete to evaluate performance. Special care must be taken when
creating these groupings in order to avoid predisposing the ML algorithm to future attacks (see
Dataset Assembly: Adversarial Partitions). In particular, the training set deeply influences an ML system’s
future behavior. Attacking an ML system through the training set is one of the most obvious ways to
throw a monkey wrench into the works.
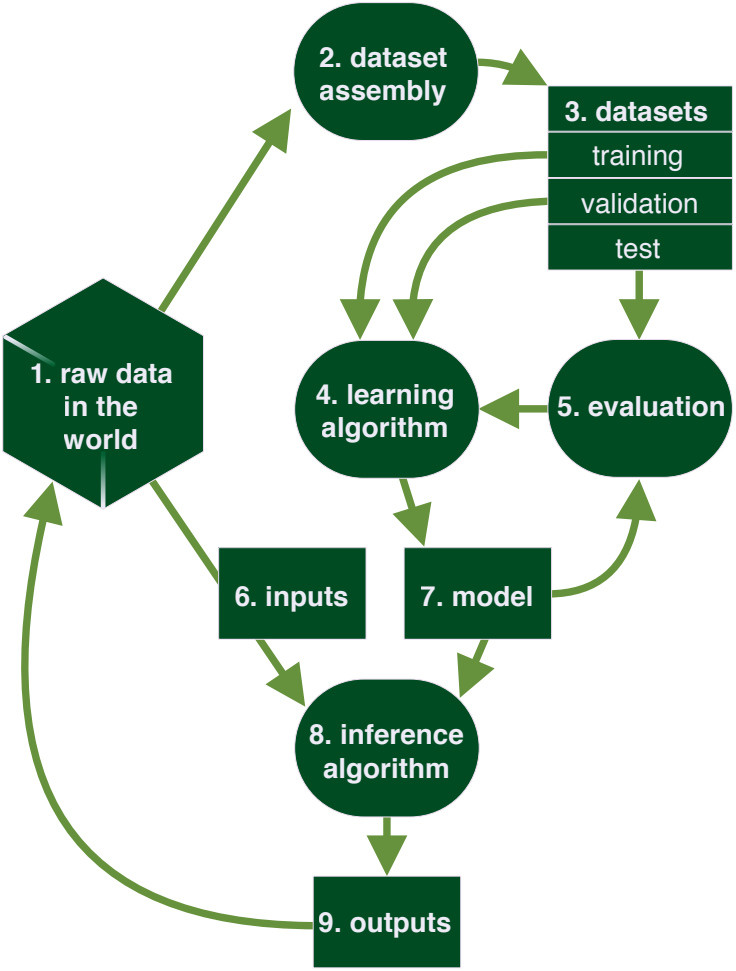
All of the first three components in our generic model (raw data in the world, dataset assembly,
and datasets) are subject to poisoning attacks whereby an attacker intentionally manipulates data
in any or all of the three first components, possibly in a coordinated fashion, to cause ML training
to go awry. In some sense, this is a risk related both to data sensitivity and to the fact that the data
themselves carry so much of the water in an ML system. Data poisoning attacks require special
attention. In particular, ML engineers should consider what fraction of the training data an attacker
can control and to what extent.12:alfeld
Many ML systems are constructed by tuning an already trained base model so that its somewhat
generic capabilities are fine-tuned with a round of specialized training. A transfer attack presents
an important risk in this situation. In cases where the pretrained model is widely available, an
attacker may be able to devise attacks using it that will be robust enough to succeed against your
(unavailable to the attacker) tuned task-specific model. You should also consider whether the ML
system you are fine-tuning could possibly be a Trojan that includes sneaky ML behavior that is
unanticipated.13:mcgraw
If training, validation, and test sets are not “the same” from a data integrity, trustworthiness, and
mathematical perspective, an ML model may appear to be doing something that it is not. For
example, an ML system trained up on six categories but only tested against two of the six may
not ultimately be exhibiting proper behavior when it is fielded. More subtly, if an evaluation set
is too similar to the training set, overfitting may be a risk. By contrast, when the evaluation set
is too different from the eventual future inputs during operations, then it will not measure true
performance. Barreno et al say it best when they say, “Analyzing and strengthening learning
methods in the face of a broken stationarity assumption is the crux of the secure learning
problem.”8:barreno
As in [raw:3:storage], data may be stored and managed in an insecure fashion. Who has access to
the data pool, and why? Think about [system:8:insider] when working on storage.
Assembling a dataset involves doing some thinking and observation about the resulting
representation inside the ML model. Robust representations result in fluid categorization behavior,
proper generalization, and non-susceptibility to adversarial input. As an example, a topic model
trained on predominantly English input with a tiny bit of Spanish will group all Spanish topics into
one uniform cluster (globbing all Spanish stuff together).
Some learning systems are “supervised” in a sense that the target result is known by the
system designers (and labeled training data are available). Malicious introduction of misleading
supervision would cause an ML system to be incorrectly trained. For example, a malicious
supervisor might determine that each “tank” in a satellite photo is counted as two tanks. (See also
[assembly:2:annotation].)
Real time data set manipulation can be particularly tricky in an online network where an attacker can
slowly “retrain” the ML system to do the wrong thing by intentionally shifting the overall data set in
certain directions.
In our view, though a learning algorithm lies at the technical heart of each
ML system, the algorithm itself presents far less of a security risk than the data used to train, test, and
eventually operate the ML system. That said, risks remain that are worthy of note.
Learning algorithms come in two flavors, and the choice of one or the other makes a big difference
from a security perspective. ML systems that are trained up, “frozen,” and then operated using new
data on the frozen trained system are called offline systems. Most common ML systems (especially
classifiers) operate in an offline fashion. By contrast, online systems operate in a continuous learning
mode. There is some advantage from a security perspective to an offline system because the online
stance increases exposure to a number of data borne vulnerabilities over a longer period of time.
An online learning system that continues to adjust its learning during operations may drift from its
intended operational use case. Clever attackers can nudge an online learning system in the wrong
direction on purpose.
ML work has a tendency to be sloppily reported. Results that can’t be reproduced may lead to
overconfidence in a particular ML system to perform as desired. Often, critical details are missing
from the description of a reported model. Also, results tend to be very fragile—often running a
training process on a different GPU (even one that is supposed to be spec-identical) can produce
dramatically different results. In academic work, there is often a tendency to tweak the authors’
system until it outperforms the “baseline” (which doesn’t benefit from similar tweaking), resulting
in misleading conclusions that make people think a particular idea is actually good when it wasn’t
actually improving over simpler, earlier method.
Part of the challenge of tuning an ML system during the research process is understanding the
search space being explored and choosing the right model architecture (and algorithm) to use and
the right parameters for the algorithm itself. Thinking carefully about problem space exploration
versus space exploitation will lead to a more robust model that is harder to attack. Pick your
algorithm with care. As an example, consider whether your system has an over-reliance on gradients
and may possibly benefit from random restarting or evolutionary learning.
Randomness has a long and important history in security. In particular, Monte Carlo randomness
versus cryptographic randomness is a concern. When it comes to ML, setting weights and
thresholds “randomly” must be done with care. Many pseudo-random number generators
(PRNG) are not suitable for use. PRNG loops can really damage system behavior during learning.
Cryptographic randomness directly intersects with ML when it comes to differential privacy. Using
the wrong sort of random number generator can lead to subtle security problems.
All ML learning algorithms may have blind spots. These blind spots may open an ML system up to
easier attack through techniques that include adversarial examples.
Some algorithms may be unsuited for processing confidential information. For example, using a
non-parametric method like k-nearest neighbors in a situation with sensitive medical records is
probably a bad idea since exemplars will have to be stored on production servers. Algorithmic
leakage is an issue that should be considered carefully.4:papernot
Noise is both friend and foe in an ML system. For some problems, raw data input need to be
condensed and compacted (de-noised). For others, the addition of Gaussian noise during pre-
processing can enhance an ML system’s generalization behavior. Getting this right involves careful
thinking about data structure that is both explicit and well documented. Amenability to certain
kinds of adversarial input attack is directly linked to this risk.14:goodfellow
An ML system may end up oscillating and not properly converging if, for example, it is using
gradient descent in a space where the gradient is misleading.
One of the challenges in the ML literature is an over-reliance on “empirical” experiments to
determine model parameters and an under-reliance on understanding why an ML system actually
does what it does. ML systems have a number of hyperparameters, including, for example, learning
rate and momentum in a gradient descent system. These parameters are those model settings not
updated during learning (you can think of them as model configuration settings). Setting and tuning
hyperparameters is somewhat of a black art subject to attacker influence. If an attacker can twiddle
hyperparameters (tweaking, hiding, or even introducing them), bad things will happen. (Also see
[inference:3:hyperparameters].)
Oversensitive hyperparameters are riskier hyperparameters, especially if they are not locked in.
Sensitive hyperparameters not rigorously evaluated and explored can give you a weird kind of
overfitting. For example, one specific risk is that experiments may not be sufficient to choose good
hyperparameters. Hyperparameters can be a vector for accidental overfitting. In addition, hard to
detect changes to hyperparameters would make an ideal insider attack.
In the case of transfer learning (see [data:2:transfer]) an attacker may intentionally post or ship or
otherwise cause a target to use incorrect settings in a public model. Because of the open nature
of ML algorithm and parameter sharing, this risk is particularly acute among ML practitioners who
naively think “nobody would ever do that.”
Determining whether an ML system that has been fully trained is actually doing
what the designers want it to do is a thing. Evaluation data are used to try to understand how well a
trained ML system can perform its assigned task (post learning). Recall our comments above about
the important role that stationarity assumptions have in securing ML systems.
A sufficiently powerful machine is capable of learning its training data set so well that it essentially
builds a lookup table. This can be likened to memorizing its training data. The unfortunate side
effect of “perfect” learning like this is an inability to generalize outside of the training set. Overfit
models can be pretty easy to attack through input since adversarial examples need only be a short
distance away in input space from training examples. Note that generative models can suffer from
overfitting too, but the phenomenon may be much harder to spot. Also note that overfitting is also
possible in concert with [data:6:online].
Evaluation is tricky, and an evaluation data set must be designed and used with care. A bad
evaluation data set that doesn’t reflect the data it will see in production can mislead a researcher
into thinking everything is working even when it’s not. Evaluation sets can also be too small or too
similar to the training data to be useful.8:barreno For more, see Luke Oakden-Rayner’s blog entry “AI
competitions don’t produce useful models” at https://lukeoakdenrayner.wordpress.com/ (accessed
10.8.19).
In some cases, evaluation data may be intentionally structured to make everything look great even
when it’s not.
Common sense evaluation and rigorous evaluation are not always the same thing. For example,
evaluation of an NLP system may rely on “bags of words” instead of a more qualitative structural
evaluation.15:reiter
Just as data play a key role in ML systems, representation of those data in the learned network
is important. When a model is crammed too full of overlapping information, it may suffer from
catastrophic forgetting. This risk was much more apparent in the early ‘90s when networks (and
the CPUs they ran on) were much smaller. However, even a large network may be subject to this
problem. Online systems are, by design, more susceptible.
In an online model, the external data set available may be so vast that the ML system is simply
overwhelmed. That is, the algorithm may not scale in performance from the data it learned on to
real data. In online situations the rate at which data comes into the model may not align with the
rate of anticipated data arrival. This can lead to both outright ML system failure and to a system that
“chases its own tail.”
Upstream attacks against data make training and its subsequent evaluation difficult.
When a fully trained model is put into production, a number of risks must be
considered. Probably the most important set of these operations/production risks revolves around
input data fed into the trained model. Of course, by design these input data will likely be structured
and pre-processed similarly to the training data. Many of the risks identified above (see especially
raw data in the world risks and data assembly risks) apply to model input almost directly.
One of the most important categories of computer security risks is
malicious input. The ML version of malicious input has come to be known as adversarial examples.
While important, adversarial examples have received so much attention that they swamp out all
other risks in most people’s imagination.16:yuan
A trained ML system that takes as its input data from outside
may be purposefully manipulated by an attacker. To think about why anybody would bother to do
this, consider that the attacker may be someone under scrutiny by an ML algorithm (a loan seeker, a
political dissident, a person to be authenticated, etc).
The real world is noisy and messy. Input data sets that are dirty enough will be
hard to process. A malicious adversary can leverage this susceptibility by simply adding noise to the
world.
If system output feeds back into the real world there is some risk that it may
find its way back into input causing a feedback loop. Sometimes this even happens with ML output
data feeding back into training data.
The same care that goes into data assembly (component 2)
should be given to input, even in an online situation. This may be difficult for a number of reasons.
When a fully trained model is put into production, a number of important risks crop
up. Note that some of the risks discussed in the evaluation risks section above apply directly in this
section as well (for example, [eval:1:overfitting] and [eval:4:catastrophic forgetting] both apply).
ML-systems are re-used intentionally in transfer situations. The risk
of transfer outside of intended use applies. Groups posting models for transfer would do well to
precisely describe exactly what their systems do and how they control the risks in this document.
Model transfer leads to the possibility that what is being reused may be a
Trojaned (or otherwise damaged) version of the model being sought out.7:shokri
ML is appealing exactly because it flies in the face of brittle
symbolic AI systems. When a model generalizes from some examples, it builds up a somewhat
fluid representation if all goes well. The real trick is determining how much fluidity is too much.
Representation issues are some of the most difficult issues in ML, both in terms of primary input
representation and in terms of internal representation and encoding. Striking a balance between
generalization and specificity is the key to making ML useful.
Most ML algorithms learn a great deal about input, some of which
is possibly sensitive (see [raw:1:data confidentiality]), and store a representation internally that may
include sensitive information. Algorithm choice can help control this risk, but be aware of the output
your model produces and how it may reveal sensitive aspects of its training data. When it comes
to sensitive data, one promising approach in privacy-preserving ML is differential privacy which we
discuss below.
Training up an ML system is not free. Stealing ML system knowledge is
possible through direct input/output observation. This is akin to reversing the model.
When a fully trained model is usually put into production, a number of
important risks must be considered. These encompass data fed to the model during operations (see
raw data risks and pre-processing risks), risks inherent in the production model, and output risks.
A fielded model operating in an online system (that is, still learning) can be
pushed past its boundaries. An attacker may be able to carry this out quite easily.
In far too many cases, an ML system is fielded without a real
understanding of how it works or why it does what it does. Integrating an ML system that “just
works” into a larger system that then relies on the ML system to perform properly is a very real risk.
Inference algorithms have hyperparameters, for example sampling
temperature in a generative model. If an attacker can surreptitiously modulate the hyperparameters
for the inference algorithm after the evaluation process is complete, they can control the system’s
behavior. (Also see [alg:9:hyperparameters].)
In many cases, confidence scores (which are paired with
classification category answers) can help an attacker. If an ML system is not confident about its
answer and says so, that provides feedback to an attacker with regards to how to tweak input to
make the system misbehave. Conversely, a system that doesn’t return confidence scores is much
harder to use correctly (and may be used idiotically). Care should be taken as to what kind of output
feedback a user can and should get.
Many ML systems are run on hosted, remote servers. Care must be taken
to protect these machines against ML-related attacks (not to mention the usual pile of computer
security stuff).
When a user decides to use an ML system that is remote, they expose their
interests (and possibly their input) to the owners of the ML system.
Keep in mind that the entire purpose of creating, training, and evaluating a model
may be so that its output serves a useful purpose in the world. The second most obvious direct
attack against an ML system will be to attack its output.
An attacker tweaks the output stream directly. This will impact the larger system
in which the ML subsystem is encompassed. There are many ways to do this kind of thing. Probably
the most common attack would be to interpose between the output stream and the receiver.
Because models are sometimes opaque, unverified output may simply be used with little scrutiny,
meaning that an interposing attacker may have an easy time hiding in plain sight.
ML systems must be trustworthy to be put into use. Even a temporary or
partial attack against output can cause trustworthiness to plummet.
Adversarial examples (see [input:1:adversarial examples]) lead to
fallacious output. If those output escape into the world undetected, bad things can happen.
In far too many cases with ML, nobody is really sure how the trained
systems do what they do. This is a direct affront on trustworthiness and can lead to challenges in
some domains such as diagnostic medicine.
Decisions that are simply presented to the world with no explanation are
not transparent. Attacking opaque systems is much easier than attacking transparent systems, since
it is harder to discern when something is going wrong.
Causing an ML system to misbehave can erode trust in the entire
discipline. A GAN that produces uncomfortable sounds or images provides one example of how
this might unfold.17:shane
See [input:4:looped input]. If system output feeds back into the real
world there is some risk that it may find its way back into input causing a feedback loop.